
Introdução ao Aprendizado de Máquina (Machine Learning) para Iniciantes
Vimos o Aprendizado de Máquina como um termo da moda nos últimos anos, a razão para isso pode ser a alta quantidade de produção de dados por aplicativos, o aumento do poder de computação nos últimos anos e o desenvolvimento de melhores algoritmos.
Aprendizado de Máquina é usado em qualquer lugar, desde a automação de tarefas rotineiras até a oferta de insights inteligentes, indústrias em todos os setores tentam se beneficiar dele. Você já pode estar usando um dispositivo que o utiliza. Por exemplo, um rastreador de fitness vestível como o Fitbit ou um assistente doméstico inteligente como o Google Home. Mas há muito mais exemplos de Machine Learning-ML em uso.
- Previsão – Aprendizado de máquina também pode ser usado nos sistemas de previsão. Considerando o exemplo do empréstimo, para calcular a probabilidade de uma falha, o sistema precisará classificar os dados disponíveis em grupos.
- Reconhecimento de imagem – O aprendizado de máquina também pode ser usado para detecção de rosto em uma imagem. Há uma categoria separada para cada pessoa em um banco de dados de várias pessoas.
- Reconhecimento de Fala – É a tradução de palavras faladas no texto. É usado em pesquisas por voz e muito mais. As interfaces de usuário de voz incluem discagem por voz, roteamento de chamadas e controle de aparelhos. Também pode ser usada uma entrada de dados simples e a preparação de documentos estruturados.
- Diagnósticos médicos – ML é treinado para reconhecer tecidos cancerígenos.
- Indústria financeira e comércio – as empresas usam ML em investigações de fraudes e verificações de crédito.
Uma história rápida de aprendizado de máquina
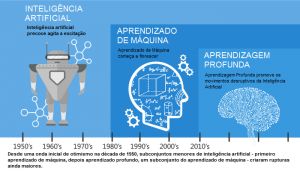
Imagem: vinculado em Aprendizado de Máquina versus Aprendizado Profundo
Foi na década de 1940, quando o primeiro sistema de computador operado manualmente, ENIAC (Electronic Numerical Integrator e Computer), foi inventado. Naquela época, a palavra “computador” estava sendo usada como um nome para um ser humano com recursos intensivos de computação numérica, então, o ENIAC foi chamado de máquina computacional numérica! Bem, você pode dizer que não tem nada a ver com o aprendizado?! ERRADO, desde o início a ideia era construir uma máquina capaz de imitar o pensamento e a aprendizagem humana.

EIMC-Integrador Numérico Eletrônico e Computador (Imagem: www.computerhistory.org)
Na década de 1950, vemos o primeiro programa de jogos de computador alegando ser capaz de vencer o campeão mundial de damas. Este programa ajudou muito os jogadores de damas a melhorar suas habilidades! Na mesma época, Frank Rosenblatt inventou o Perceptron, que era um classificador muito, muito simples, mas quando foi combinado em grande número, em uma rede, tornou-se um poderoso monstro. Bem, o monstro é relativo ao tempo e nesse tempo, foi um verdadeiro avanço. Então, vemos vários anos de estagnação do campo da rede neural devido a suas dificuldades em resolver certos problemas.
Graças às estatísticas, o aprendizado de máquina tornou-se muito famoso nos anos 90. A interseção entre ciência da computação e estatística deu origem a abordagens probabilísticas em IA. Isso mudou o campo ainda mais em direção a abordagens baseadas em dados. Disponibilizando dados em grande escala, os cientistas começaram a construir sistemas inteligentes capazes de analisar e aprender com grandes quantidades de dados. Como destaque, o sistema Deep Blue da IBM venceu o campeão mundial de xadrez, o grande mestre Garry Kasparov. Sim, eu sei que Kasparov acusou a IBM de trapacear, mas isso é um pedaço da história agora e Deep Blue está descansando pacificamente em um museu.
O que é aprendizado de máquina?
De acordo com Arthur Samuel, os algoritmos de Aprendizado de Máquina permitem que os computadores aprendam com os dados e até melhorem a si mesmos, sem serem explicitamente programados.
O aprendizado de máquina (ML) é uma categoria de um algoritmo que permite que os aplicativos de software se tornem mais precisos na previsão de resultados sem serem programados explicitamente. A premissa básica do aprendizado de máquina é construir algoritmos que possam receber dados de entrada e usar a análise estatística para prever uma saída enquanto atualiza as saídas à medida que novos dados se tornam disponíveis.
Tipos de aprendizado de máquina?
O aprendizado de máquina pode ser classificado em 3 tipos de algoritmos.
- Aprendizado supervisionado
- Aprendizagem não supervisionada
- Aprendizado por Reforço
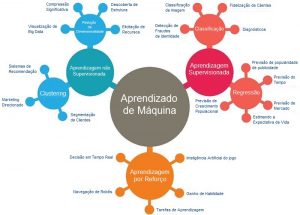
3 tipos de aprendizagem
Visão Geral do Algoritmo de Aprendizado Supervisionado
Na aprendizagem Supervisionada, um sistema de IA é apresentado com dados rotulados, o que significa que cada dado é marcado com a etiqueta correta.
O objetivo é aproximar a função de mapeamento tão bem que, quando você tem novos dados de entrada (x), é possível prever as variáveis de saída (Y) para esses dados.
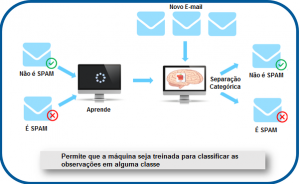
Exemplo de Aprendizagem Supervisionada
Como mostrado no exemplo acima, inicialmente pegamos alguns dados e os marcamos como ‘Spam’ ou ‘Não é Spam’. Esses dados rotulados são usados pelo modelo de treinamento supervisionado, esses dados são usados para treinar o modelo.
Uma vez treinado, podemos testar nosso modelo testando-o com alguns novos e-mails de teste e a verificação do modelo é capaz de prever a saída correta.
Tipos de aprendizagem supervisionada
- Classificação: Um problema de classificação é quando a variável de saída é uma categoria, como “vermelho” ou “azul” ou “doença” e “nenhuma doença”.
- Regressão: Um problema de regressão é quando a variável de saída é um valor real, como “dólares” ou “peso”.
Visão Geral do Algoritmo de Aprendizado Não Supervisionado
Na aprendizagem não supervisionada, um sistema de IA é apresentado com dados não categorizados e não categorizados, e os algoritmos do sistema atuam nos dados sem treinamento prévio. A saída é dependente dos algoritmos codificados. Sujeitar um sistema a aprendizado não supervisionado é uma maneira de testar a IA.
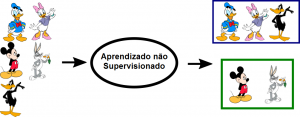
Exemplo de Aprendizagem Não Supervisionada
No exemplo acima, nós demos alguns caracteres ao nosso modelo que são ‘Patos’ e ‘Não são Patos’. Em nossos dados de treinamento, não fornecemos nenhum rótulo aos dados correspondentes. O modelo não supervisionado é capaz de separar os dois caracteres observando o tipo de dados e modelando a estrutura ou distribuição subjacente nos dados para aprender mais sobre eles.
Tipos de aprendizagem não supervisionada
- Clustering: um problema de clustering é onde você deseja descobrir os agrupamentos inerentes nos dados, como agrupar clientes por meio do comportamento de compra.
- Associação: um problema de aprendizado de regra de associação é onde você deseja descobrir regras que descrevam grandes partes de seus dados, como as pessoas que compram X também tendem a comprar Y.
Visão Geral da Aprendizagem por Reforço
Um algoritmo de aprendizado de reforço, ou agente, aprende interagindo com seu ambiente. O agente recebe recompensas executando corretamente e penalidades por executar incorretamente. O agente aprende sem a intervenção de um humano, maximizando sua recompensa e minimizando sua penalidade. É um tipo de programação dinâmica que treina algoritmos usando um sistema de recompensa e punição.
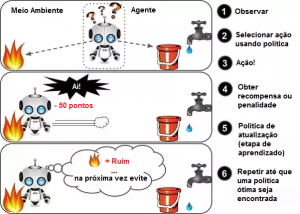
Exemplo de Aprendizagem por Reforço
No exemplo acima, podemos ver que o agente recebe 2 opções, isto é, um caminho com água ou um caminho com fogo. Um algoritmo de reforço funciona na recompensa de um sistema, ou seja, se o agente usa o caminho do fogo, então as recompensas são subtraídas e o agente tenta aprender que deve evitar o caminho do fogo. Se tivesse escolhido o caminho da água ou o caminho seguro, alguns pontos teriam sido adicionados aos pontos de recompensa, o agente então tentaria descobrir que caminho é seguro e qual caminho não é.
É basicamente aproveitando as recompensas obtidas, o agente melhora o conhecimento do ambiente para selecionar a próxima ação.
Fonte: Towards Data Science – Ayush Pant. Introduction to Machine Learning for Beginners (https://towardsdatascience.com)